Typical workflow¶
The number of nodes in the standard library can be quite daunting for a new user, so let us go through a few common use cases to get acquainted with some of the types of nodes that you can find.
Importing data¶
To import data from a file or a database you first need to add a Datasource or File Datasources node (Input/Import/Datasources in the library view) to the workflow. Configure the Datasource(s) node to point to where your data is located. Connect it to a type node like Table(s) (Input/Import/Table in the library view) or ADAF(s) (Input/Import/ADAF in the library view) and you should be good to go. The type nodes can often automatically detect the file format and read the file without any additional configuration, but sometimes you need to open the configuration GUI, manually choose the file format, and complete some configuration specific for that file format.
Prepare data¶
Typically, data needs to be prepared by removing invalid values and unwanted noise from the data before it is analyzed. This may also include removing irrelevant columns to save execution time and storage space.
When working with Tables two basic nodes useful for washing data are: Select rows in Table and Select columns in Table. Their function is fairly self-explanatory.
Analyze data¶
There are three different approaches to analyzing data in Sympathy. The fastest and easiest is to use the Calculator List node. The Calculator List node supports small computations and is far from feature-complete at this stage. It only operates on Table data.
The second approach is to use the function selector f(x) nodes. The function selector supports all datatypes. The f(x) nodes are typically used to define functions that will be used in many different workflows.
The third approach is to write a full Sympathy node. This requires more work but is necessary to implement custom behaviour beyond that which is possible in the f(x) or Calculator List nodes. Refer to the Node writing for information about how to write full Sympathy nodes.
Export data as plots or reports¶
Exporting is useful for storing intermediate or final results from a workflow.
The output from any function node can easily be exported by connecting an export node, such as, for example, Export Tables - when dealing with table data, and Export ADAFs for ADAF data. Notice that the exporter names are in plural, which means that they work on list type input. To export table data using Export Tables, the Item to List node can be used to produce the desired table list type. The export nodes are different from the import nodes in that they do not use an external data source, instead, the output location is set in the node’s configuration. Export nodes exist for many of the same file formats as the import nodes, making it possible to do import, analysis, and then export back to the original input source.
For visualization, a few different nodes are available for plotting and reporting. The most powerful set of plotting and reporting nodes are in the reporting library.
Working with ADAF¶
Many of the nodes in the standard library are only available for Table data. If your data is more naturally represented as ADAF you can still use those nodes by letting them work on the tables that make up the ADAF. For instance if I have imported some data as an ADAF, but I want to remove some of the time series from one of the rasters. The node ADAF to Table lets me get the relevant raster as a table and I can then use the node Select columns in Table to remove some of the columns. As a last step I can use the node Update ADAF with Table to place the modified Table back into the ADAF.
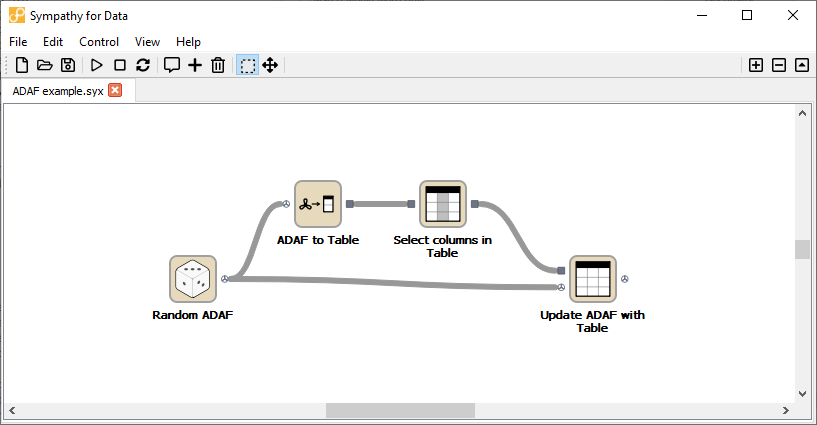
Example of working with ADAF. This workflow can be found in <sympathy examples>: Misc/ADAF example.syx.¶
Control structures¶
Things like loops and if-statements are not as ubiquitous in sympathy workflows as they are in ordinary programming languages. They are instead often implemented in a more data-centric way.
Conditional execution¶
If you want to branch a flow and only execute a single branch, you can often get away with using filters and selectors to guide the data into different branches. For more complex conditional execution, use the node Conditional Propagate.
Looping¶
The easiest way to loop over data in Sympathy is to use list nodes. Most list nodes implicitly loop over all the incoming data. For example Select columns in Tables will loop over all the tables in the input and do the selection for each of them.
For the situations when there is no list node for what you need to do you can instead use the node Map to run a Lambda once for each element in a list.
